Observations from External Projects
CATcher:
MarkBind:
RepoSense:
TEAMMATES:
- CHANG WENG YEW, NICOLAS
- DOMINIC LIM KAI JUN
- JAY ALJELO SAEZ TING
- KEVIN FOONG WEI TONG
- MOK KHENG SHENG FERGUS
- NEO WEI QING
- ONG JUN HENG, CEDRIC
- SIM SING YEE, EUNICE
- ZHANG ZIQING
CATcher
GOH YEE CHONG, GABRIEL
Project: FreeCodeCamp.org
An open source platform providing free resources to learn coding.
My Contributions
Give a description of your contributions, including links to relevant PRs
Merged fix(curriculum): update instructions for step 110 for rpg project #53564
Awaiting Review fix(client): Add live image URL validation for portfolio images #53617
Adding image URL validation for frontend
Learnt how we can use image() html object to verify if the image URL is live.
Debugging CI/CD tests
Learnt that the previous test cases can affect the next test cases, so I should run all test cases in order to check if there's problems with loading and saving state.
Learnt to check if I forgot to check logic with loading saved states (adding a portfolio section in user settings, and loading that section portfolio)
My Learning Record
Give tools/technologies you learned here. Include resources you used, and a brief summary of the resource.
Setting up a GitHub repository with Windows Subsystem for Linux (WSL)
Learnt to use VSCode to access code on the WSL. Git clone repository on the WSL, not on windows.
Discord server and forums
FreeCodeCamp has live Discord server and forums with active and dedicated contributors.
Setting up was difficult, and while instructions could be clearer separated into Windows and Mac users (for Windows users, for Mac users), it was good they had detailed instructions.
Wait time for help
As with all open source projects, getting help or code reviews can take time. I was fortunate my first PR was an easy fix and quickly reviewed within 15 mins, but my second PR is still awaiting review. Nonetheless, the contributors are helpful and helped point out the cause of my CI/CD issues.
VIGNESH SANKAR IYER
Project: Zitadel
Zitadel is an open source user management tool that aims to provide easy identity infrastructure, with out-of-the-box features such as
- Multi-tenancy with team management
- Secure Login
- Self-service
- OpenID Connect
- SAML2
- LDAP
and more solutions. It provides easy integration with oAuth providers such as GitHub, Facebook, O365 and serves as an easy way for enterprises to set up multi-tenancy identity providers with clear separation of identities. Zitadel is written in Go and consists of an interesting mix of server-side rendered authentication (using Go and HTML templates), along with a client side application written in Angular, as well as modularised Core library that uses Event-driven architecture to ensure that all events are not only captured but also traceable.
The team favours transaction safety, with high availability, and have employed and implemented it's own message queue system. It works by placing events into an in-memory queue for subscribers, under the pub-sub model.
Zitadel has 7.1k stars and is used by many organisations as an alternative to other identity infrastructure platforms, due to it's heavy customisability in terms of branding and deployment options.
My Contributions
- Fixed button positioning issues on email verification screen within the Login page PR #7579
- Fixed navigation issues where users would be directed incorrectly to another page when clicking on "Back" PR #7683
My Learning Record
Deploying both an Angular console application, which is a management interface, as well as Server side pages for authentication (Login, Register and Password Reset pages) were important. Particularly, Zitadel uses HTML templates heavily along with a flexible component system that enables easy internationalisation, which is important for a tool like Zitadel that everyone can use.
Also, learning about gRPC through interactions with the backend was also enlightening as I was more familiar with GraphQL and traditional HTTP endpoints through my experience with CATcher/WATcher and personal projects and internships.
gRPC uses Protocol Buffers (protobufs) by default, which is a lightweight, highly efficient serialization tool; which serves it's purpose when building a distributed application like Zitadel. It also allows for server-side and client-side streaming, both of which are used (particularly for event logging) in Zitadel.
Project: Templ
Templ is a HTML templating language for Go that has great developer tooling, including an LSP (Language Server Protocol) for Vim users and extension for VSCode users. With Templ, we can create components that render fragments of HTML and then compose them to create screens, pages, documents or apps.
This allows for
- Server-side rendering (deployed as a serverless function or standard Go program)
- Static rendering (create static HTML files to deploy how you choose)
- Compiled code (components compiled to performant Go code)
- Ability to move away from JavaScript in client-side and server-side contexts
Templ borrows heavily from the Component model in React and Angular, and as such models it's own components as mark up and code that is compiled into functions that return a templ.Component interface.
This allows for Templ to be used in tandem with htmx, to selectively replace content within a webpage instead of replacing the whole web page within the browser.
My Contributions
My Learning Record
I learnt how to build an SSR application using Go, HTMX and Templ by building an example application to provide documentation for i18n support. I also used Server-side Events which enabled minified HTMX runtime to add elements based on the component that was received on the stream endpoint. I also understood how i18n was generally implemented on products with a need to support a variety of languages, as well as building generalised components that decoupled the actual components from the textual UI.
Project: FerretDB
FerretDB was founded to become the de-facto open-source substitute to MongoDB. FerretDB is an open-source proxy, converting the MongoDB 5.0+ wire protocol queries to SQL - using PostgreSQL or SQLite as a database engine.
MongoDB was originally the eye-opening technology for developers that allowed developers to build applications faster than using relational databases. However, with MongoDB abandoning its open-source roots, there was a need for an easy-to-use open-source document database solution, which is what FerretDB aims to fill.
My Contributions
- Add local changelog generation that uses a milestone title to generate the batch of changes for the milestone PR #4219
My Learning Record
While I did not learn much about the database design in itself, I learnt about Conventional Commits: a standardised format that dictates how developers should write their commit messages. Conventional commits allowed for projects with a large developer base to have visibility and transparency over who did what, when. Furthermore, the standardisation allows for easy automatic changelog generation, important for when products are shipped out to actual users; as well as making it easier for people to contribute to projects.
FerretDB suffered from the lack of implementation of Conventional Commits: without it, it was dependent on the platform (GitHub) the repository was hosted on to actually generate meaningful Changelogs. This added additional dependencies that tied the project with GitHub unnecessarily, instead of allowing the project to be independent of the Git versioning platform it was hosted on (GitLab, BitBucket are suitable alternatives).
As such, Changelog generation was originally done by using the GitHub workflow directly, which overly complicated the release process, necessitating for another way to locally generate the Changelog.
WONG CHEE HONG
Project: SourceAcademy Frontend
Sourceacademy is the an online experiential environment used for teaching students computational thinking and is used by the School of Computing in NUS and Uppsala University in Sweden to teach introductory programming modules. The frontend is built using React and Redux.
My Contributions
In this project, I have authored and merged two PRs. They are listed as follows:
Fix double window prompt when uploading users #2943
In this PR, I fixed a long standing bug regarding the UI where two file prompts show up upon clicking a "upload csv" button. To solve this, I first reproduced the issue on my local development environment, and then identified the issue, which happened to be the incorrect use of a
<FileInput>react component within a<CSVReader>component. The components were imported from a theming library and a CSV parser library respectively.-
In this PR, I laid the groundwork for future internationalization work to be done on SourceAcademy. SourceAcademy started out as a project in NUS but has plans to go international, as seen by its use in Uppsala university in Sweden. As such, adding i18n to the project will be crucial for its future.
In this PR, I introduced the use of
react-i18nextlibrary, as well as define data structures to allow future translators to easily add on new translations and languages.
My Learning Record
React & Redux
Sourceacademy is built in React and Redux, and as such, I have had to learn how to work with these two libraries. While I have used React and Redux before, I have not seen how it can be used in a large scale project like Sourceacademy. In Sourceacademy, I have seen how Redux and Redux Toolkit was used to create a typesafe global state that is shared across the entire application and I appreciate how well structured the code was in the repository.
i18next
i18next is a library that allows for internationalization in a React project. It is a powerful library that allows for easy translation of text in a project. During my implementation of the i18n framework in Sourceacademy, I referenced several implementations of i18n across various established open source repos such as HospitalRun and FreeCodeCamp for any best practices. From these references, I learned how to structure the i18n files and the various translation resources to make it easy for future translators to add on new translations.
Furthermore, the i18n framework that I contributed to has strong type safety and only allows keys that are defined in the translation files to be used, making it easier for future developers to see what keys are allowed on what file. I am grateful for the Sourceacademy maintainers for their guidance in this implementation.
Practices and tools from SourceAcademy that could be adopted by CATcher
SourceAcademy utilises Yarn as their package manager. From almost all points of view, yarn has the exact same functionality as npm, but it is faster and more reliable. As such, we could consider moving over to using Yarn in CATcher as well.
Furthermore, I was particularly impressed with the testing framework that they had to ensure any new changes were not breaking. They made use of jest and had an interactive UI test runner that allowed the developer to see which tests were failing and why. This is something that CATcher could consider adopting as well.
MarkBind
ELTON GOH JUN HAO
Projects I have worked on
Mattermost
Mattermost is an open-source collaboration platform designed for secure communication throughout the entire software development lifecycle. It serves as a self-hostable alternative to Slack, offering similar functionalities with the added benefit of full control over hosting and management.
Twenty
Twenty CRM is a modern, open-source Customer Relationship Management (CRM) platform. It serves as an self-hostable alternative to Salesforce.
My Contributions
In the mattermost PR (merged). I addressed this issue where the CLI command to list the teams uses a magic number of 9999. Utilizing such large magic numbers presents two problems: it restricts the ability to list more than 9999 teams and could result in a request that is too large. To solve this, I implemented pagination for the request, with each page containing 200 teams. Subsequently, I updated the test cases to reflect the new expected behavior.
In the Twenty PR (merged). I addressed an issue reported by a user concerning LinkedIn school URLs not parsing correctly. Upon investigating the issue on the frontend, I discovered that the existing regex was only configured to support company URLs. To resolve this, I updated the regex to also accommodate school URLs and conducted tests to ensure the fix was effective.
My Learning Record
gomock
I have learned to use GoMock, a mocking framework for Golang, which streamlines the creation of mock objects for unit testing. It helps with decoupling components, enabling the simulation of complex behaviors and interactions. I am surprised how easy it to use to mock complex behaviours. Will definitely use it for Golang testing next time!
Resource used:
Yarn workspaces
Yarn Workspaces is a feature of Yarn that simplifies handling multiple packages within a single repository by enabling shared dependencies and centralized script management. I learnt Yarn Workspaces while setting up the repository for the Twenty project. Overall, it is a good experience as I learnt more alternatives to Lerna and NPM workspaces.
Resource used:
Practices/tools from Mattermost that could be adopted by Markbind
I was particularly impressed with the Twenty's onboarding guide because it includes multi-OS setup guides and instructions on setting up through Docker containers. Furthermore, it provides an IDE setup guide, and its repository contains a .vscode/extensions.json file that assists users in configuring VS Code. For Markbind, while the Docker container setup may not be necessary, adopting a multi-OS guide could be beneficial. It could promote useful tools like nvm for testing across multiple Node.js versions, and a VS Code extensions list could help new developers adhere to our coding practices.
I was really impressed with the PR review workflow at Mattermost. It's incredibly systematic, featuring stages such as UI review, Dev review, and QA review, which make the process feel seamless. Additionally, they utilize bots to remind reviewers to complete their reviews. While Markbind is smaller and might not require such an elaborate setup, investigating the potential of GitHub PR bots could be beneficial. These tools could streamline our review process and ensure that contributions are efficiently and effectively vetted.
HANNAH CHIA KAI XIN
Project: Godot
While I was not able to make a contribution to the main repository, as I was using this software and following development discussions I'd like to share my understanding. Additionally, I made a PR to the documentation repository which I will elaborate on later.
Godot is an open-source game engine, which can also be used to create other GUI centric applications such as RPG map makers. I have used Godot for a few games so that I could familiarise myself with the tool from the user perspective.
User experience
One area where Godot is strong is the new-user experience. It offers multiple ways to get started: a free playable desktop tutorial, step-by-step tutorial based documentation for 2d or 3d games, youtube video tutorials, primers to the overall concept, as well as active community support in the forum, discord, or over other social media platforms like Reddit.
With MarkBind, this lends validation to the idea that we might want to also have multiple ways to get started. This informed my thoughts on this issue Add a set of tutorials for MarkBind which I added to the overall pinned goal to Make it easier for users to get started with markbind
Arrangement of repository and maintenance
It's clear that Godot is a huge project - they even have a development fund from donors, and I believe there are people paid to work on the project full time. Nevertheless, it seems that while there is an active developer community there is also an abundance of work and limits on attention. Furthermore, with such a big project and so many issues, this is a project that uses an organisation to group many active repositories - the main godot repository, as well as godot-docs and godot-proposals are some examples. godot-proposals are used for new feature requests and has 4.2k issues as well as discussions! godot has over 5k issues - and over 2.4k PULL REQUESTS. This is an huge volume especially considering that it is an active repository - pull requests are closed or merged daily.
Decision Making: Godot mantainers discuss new features over PR meetings that happen on a regular basis before asking community members to work on them. Given the volume of requests and the number of users using the program, adding new features depends on certain principles. There has been some discussion over this issue that was very interesting: Godot Engine's vision and development philosophy should be better formalized or easily accessible #575
(This user was later was banned from the organisation and wrote a book about the experience)
Leaving aside the drama, the point around "What direction does an open source repository go" was very intersting to investigate, though I haven't yet come to any conclusion. This is the source of one of my suggestions to the CS3282 team to document some of the design principles in MarkBind such as extensibility, so as to aid in new batches making decisions about the project. Right now, a lot of this knowledge only lives in a few people (like prof Damith). This could lead to a loss of knowledge in the future and inconsistency in the project.
Sphinx
I tested out this open source documentation when working on the Godot documentation.
- This Medium article is a good upfront summary of setting up Sphinx. As you can see from the article, the set up process is not trivial.
- Sphinx does offer some good features such as strong search, layouts and versioning. There seem to be other features which might be worth evaluating for MarkBind
- In my exploration with using Sphinx to run the Godot documentation, one part was very frustrating - I hated not being able to hot reload the docs as I wrote them; you have to run an additional command. This feature is very useful for MarkBind.
HSR Optimizer
HSR Optimizer is a tool built to help Honkai:Star Rail players figure out how to build their characters by helping to abstract some of the math away in a user friendly interface.
They are very light on documentation - essentially just the getting started and CONTRIBUTING.MD pages. To compensate for this, the discord server where development takes place is very active, and new developers are encouraged to hop over and ask questions. One advantage I noticed form having a very light set of documentation is you feel empowered to start pretty fast, as you aren't worried that you've missed something that isn't written down. However, this also does restrict some communication to a more closed platform, and knowledge about the architecture and why certain decisions are made is totally opaque unless someone calls it out explicitly. Furthermore, code comments/discussion may also occur primarily in Discord.
An active, up to date issue tracker is mantained by the main developer, which uses a simple format of "Motivation" and "Goal" and also uses the GitHub project tracker to manage all issues. One thing I really liked about the issue tracker is that it mainly uses only two criteria - priority and size - but this is very effective as a contributor to understand what is worth working on. XS PRs only involve a small amount of code, and the are good PRs to try in multiple categories. The quick response from developers was very motivating when exploring this project.
One nice aspect of the project is it is dogfooded by the creator and there's fairly close communication with a passionate community, so there is a clear motivation for features which are asked for and developments made. This is aided by a very clear value proposition to Honkai: Star Rail players.
React-Admin
React-Admin is a tool to build CRUD apps for business usecases very quickly. It's robust, flexible, and very easy to use. As a result, it is well adopted by the industry. I explored this project and used it for another project I was doing this semester, and also presented on this for tech talks.
Some interesting aspects:
- Funded by Enterprise - since they can pay staff and have active paying customers, they have a well-organised and updated repository as well as regular updates of both the free content and the paid/locked content
- That funding seems to have a chilling effect on outside contributors (I think), as most PRs seem to be by the team; but deprioritised issues are up for grabs by the outside community. But that isn't such a downside considering the team is unlikely to have to spend time on mentoring or helping out new contributors
- Demo pages that show features and are navigable by users. The features that are used are clearly signposted. Looking at these demo pages informed some of the issues I created fro MarkBind in terms of making things easier for new users to get started - an example is my suggestion to link netlify demo pages for new users to click around in.
- Codepen for the example makes it even easier to understand how everything fits together and use exactly what is used in the examples. Markbind seems to do a similar thing with netlify deploy buttons, but with a higher barrier to entry because you must make a repo in your own account
- Ability to guess what the shape of user data looks like to get started even more quickly. It would not be trivial but the
markbind init --convertcommand could be improved to better guess the shape of the user website
Supabase
Supabase. I learned: what it is and how to use it and it's capabilities. Example: learned that it can implicitly do joins
godot-supabase
This is an addon for godot, that helps to streamline the use of supabase in godot, where it can be used as a backend. godot-supabase is not actively updated or mantained, which was also pretty discouraging for me to PR on it... I considered it since I was using it, but it seems it may not be commonly used either. This was a good experience for me to try a less-wellknown opensource repository. It was extremely useful to me, which is a good example of how open source can help people you don't know anything about.
While documentation was relatively sparse, one advantage of the way the user developed it was by creating demos using the system and making those code repos public - though the web based demos went down, the code was still up on Godot and very helpful to figure out syntax.
My Contributions
Give a description of your contributions, including links to relevant PRs
After the precommit hook was added in the godot repository, there had to be documentation added for it. I took this up because it seemed to me to be something that would affect a lotof new developers, but even though I had 3-4 reviews, it took around a month to merge, which discouraged me from trying to merge something to the Godot repository. This PR also demonstrates the rate of change and development in Godot - after the commit hook improvement was made, only a few weeks later the decision was made to change one of the linting tools - which would also modify the documentation I had written as the precommit hook helped to lint using that tool.
This PR modified the UI to meet user demand. I think the most interesting part of this PR was the user demand aspect - the issue originated in the discord server, where the user shared their case and that helped to surface the need for the PR. The PR was very very well-scoped - great way to familiarise with code style and the related aspect of the repo while limiting problems. Doing this PR also was useful in using Ant design.
- [Bug] Recalculate score for saved builds #170 - investigated & PR merged
Here is my transferred comment with explanation summarising discord discussion
There are use cases where you might not want to update your saved build with the most recent algorithm, such as with characters who can have multiple build profiles: (see #35 for more discussion. When #35 is implemented, scores will eventually be attached to scoring profiles instead of characters. The build itself should be saved with a profile attached to it instead of the behaviour we have now in the fix)
One obvious issue with mantaining build's score based on the scoring algorithm when it was saved is the user will probably forget what their custom settings were, and it'd be a whole bunch more (out of scope) work to make a UI that makes sense for this.
so the fix for this bug is just to get the two numbers to match by updating the saved builds since "we want to score both the character and its saved builds by the current user defined scoring algorithm".
This feature was interesting to me because of how it interfaced with the game itself. Because there are multiple ways to develop a character, players might want to score / optimise their character to different stats. This was an interesting mid-point solution working towards a bigger solution in the future (multiple saved builds)
It was also interesting how data was separated. Originally I wrote this PR to call a function from the data class (separation of concerns) but as the data class is in .js and not .ts (slow migration) and the feature is relatively isolated, they suggested I put it all into one file where it was called instead.
RepoSense
CHARISMA KAUSAR
Project: date-fns
date-fns is a modern TypeScript date utility library. It provides the most comprehensive, yet simple and consistent toolset for manipulating JavaScript dates in a browser & Node.js.
It is like Lodash for dates. It has 200+ functions to manipulate dates, is modular and immutable, uses native dates, provides I18n support, and is built using pure functions.
The project has a main library, date-fns, and a documentation website, date-fns.org.
My Contributions
Having utilized the date-fns library in an event management system previously, I decided to contribute to the project. I did this by setting up the function aliases system and then focused on improving Duration support.
Function Aliases and Documentation Site
My first PR was to add aliases to functions in date-fns. I added an alias formatDate for the format function in PR#3653 and reached out to the project maintainer @kossnocorp for guidance regarding long-term contributions and getting more PR visibility. He agreed to provide weekly reviews to facilitate my contributions and we set up a communication channel on Discord.
He suggested that I work on the documentation website, date-fns.org as the docs did not support displaying function aliases yet. I then added aliases to functions in the TypeDoc documentation website in PR#216.
Duration Support
Next, as per the project's current needs shared by the maintainer, I focussed on improving Duration support in date-fns. I submitted a proposal to improve Duration support to the project maintainer and got started with reviewing issues and PRs related to Duration support. Since one of the PR authors was unresponsive, I took over the PR, fixed the issues, added extensive tests and updated the documentation in PR#3768 for parseISODuration.
Timeline of Contributions
| Date | Contribution | Links |
|---|---|---|
| 08 Jan 24 | Authored PR #1 | Add alias formatDate for format function #3653 |
| 11 Jan 24 | Authored PR #2 | Add aliases to functions in typedoc #216 |
| 11 Jan 24 | Created issue | Blockstyle quotes not readable in light mode #217 |
| Week 2 | Reviewed PR | Add alias isExisting for isExists #3673 |
| Week 2 | Submitted proposal | Proposal to improve Duration support, Discussion comment |
| Week 3 | Contributed to discussion | Formatting duration options #3693 |
| Week 3-5 | Reviewed PR | feat: add parseISODuration #3151 |
| Week 6-8 | Suggested improvements | ExtendedDuration and Temporal proposal |
| Week 12-13 | Authored PR #3 | Add parseISODuration function #3768 |
Other Projects
Before date-fns, I also tried contributing to other OSS projects to make a decision on which project to choose.
matplotlib
When applying for CS3281, I contributed to matplotlib, a Python plotting library. I added an ellipse class for annotation box styles in PR#24596. The PR was merged and I learned how to contribute to open-source projects by following the contributing guide. The maintainers were responsive to issues and PRs; however, I sought a project that aligned better with my interests and chosen area of expertise.
react-awesome-loaders
I also tried contributing to react-awesome-loaders, a React component library, in Dec 2023. Although the library had amazing loader designs, it used Node 12 and could not be utilized in modern projects using Next.js, which has a minimum Node requirement of Node 18. I successfully updated the node version in the project and used ncu or npm-check-updates to update old dependencies in PR#24. Unfortunately, the documentation site could not be updated as it was created with smooth-doc, which was not compatible with Node 18. Considering that I needed to migrate the entire documentation site to a new framework, I put the PR on hold and it was not merged.
checkstyle
Then I tried my hand at checkstyle, a Java static code analysis tool, in Jan 2024. I removed //ok comments for the equalavoidsnull module in PR#14215 and the PR was merged. The project maintainers were responsive and the issues for new contributors were handpicked by maintainers and labelled as "good first issue", "good second issue", "good third issue" and "good fourth issue" (1 - 3 each). This facilitated easy identification of issues for new contributors and progression through the contribution process.
My Learning Record
1. Tools and Technologies
1.1 Learning why date-fns over others
Working with a popular npm package, I learned extensively about the library's perks from the documentation itself. I discovered that date-fns utilizes tree-shaking to reduce the size of the final bundle and read the webpack documentation to understand its functionality. Tree shaking involves dead code elimination to ensure production-ready code with minimal file size, allowing compatibility with tools like webpack, Rollup, etc.
The project also employs a function-based API where each function is a pure function, enabling better immutability and testability. Moreover, it allows for importing only the necessary functions, enhancing performance. Additionally, the project offers a functional-programming submodule facilitating improved function composition, which allowed revisiting some concepts taught in CS1101S.
1.2 Testing npm packages
Since I worked on an npm package, I learned various methods to test npm packages locally beyond standard unit testing. Instead of repeatedly publishing the package to npm (which I would have done a year ago -_-), I utilized npm link to test the package locally in other JavaScript projects. I learned about this approach from Urban Sanden's blog. Additionally, I used npm tsx to get a TypeScript REPL (Read-Eval-Print-Loop) and required the respective date-fns function to test them within the terminal. This was facilitated by tsx, which stands for TypeScript Execute, and enables running TypeScript in Node.js with improved Developer Experience (watch mode, scripts, etc).
1.3 Generating documentation
date-fns uses TypeDoc to generate documentation for the project. I used the official TypeDoc docs to understand its functionality. The documentation site generator created documentation based on the TSDoc comments deployed on Firebase. The TSDoc standard was used for documenting the code, akin to JavaDoc. Having worked with multiple TypeScript projects before, this was my first experience using a TypeScript documentation generator, and it was smooth and convenient.
1.4 Date manipulation in JavaScript
Exploring the history of date manipulation in JavaScript and its evolution over time was enlightening. I learned about various methods for date manipulation in JavaScript and compared date-fns with competing libraries like Moment.js and Day.js.
Additionally, considering date-fns aims to improve Duration support, I explored the experimental ECMAScript Temporal proposal that seeks to provide native support for Durations in JavaScript. This proposal could potentially enhance duration functions without using our library, however, polyfills like these tend to be heavy, prompting date-fns to implement a lightweight solution as an interim API with a minimal subset of the Temporal proposal.
2. Reflections on contributing to date-fns
date-fns has a Contributing Guide detailing how to contribute to the project.
2.1 Good: No more "Move fast and break things"
Having worked in fast-paced environments before, I generally embrace the "move fast and break things" mentality (maybe a bit too much :3 -> RepoSense issues #2164 and #2184). However, you do not have that "freedom" when working on an npm package with 20 million weekly downloads. This was a good learning experience for me as even a simple function such as parseISODuration required extensive discussions regarding design decisions, for example, whether undefined values should be preserved, what rules should be followed for parsing, etc., and all these should consider the standard proposals, the competitor libraries' features, and the community's feedback.
2.2 Good: Making a difference
While many other OSS projects I contributed to involved fixing bugs or adding small features, date-fns was more about making a difference. Since date-fns is a modular library with pure functions, contributors get to work on actual features that can be used by millions of developers worldwide. This was a great motivation for me to contribute to date-fns.
2.3 Good: Targeted mentorship
I reached out to the maintainers of date-fns and they were very helpful in guiding me on how to contribute to the project. This helped me work on the project for a longer period of time and make more meaningful contributions based on the project's needs instead of randomly picking issues to work on.
2.4 To improve: Community management
date-fns has a large community and a lot of issues are opened every day. However, the 3-5 maintainers of the project do not have the bandwidth to manage all the issues. This makes it difficult for new contributors to find issues to work on. Moreover, repetitive issues are opened multiple times, leading to duplicated efforts in PRs. This is something that can be improved in date-fns.
Since there are too many PRs opened, the maintainers have decided to only focus on those PRs that contribute towards the project's long-term goals, which is a good strategy to ensure that the project is moving in the right direction. Sometimes, contributors are not responsive to maintainers' feedback and this leads to abandoned PRs. Instead of starting from scratch, I learned how to handle abandoned PRs by taking over one and completing the work.
2.5 To improve: Documentation contrasts
While date-fns has a very comprehensive documentation website, the documentation website generator did not have any contribution guidelines, because it was mainly handled by the core team. This made it difficult for me to understand how to contribute to the custom documentation website generator, and I had to reach out to the maintainers for guidance. This is understandable as the documentation site generator does not expect much community contributions, but is still something that can be improved in date-fns.
3. Suggestions for RepoSense
3.1 One-to-one mentorship
date-fns has a system where maintainers provide weekly advice to contributors to help them make meaningful contributions to the project. This is a great way to guide new contributors and help them understand the project better. This is something that can be adopted by RepoSense to help new contributors make contributions that align with project goals.
3.2 Automatic documentation generation
Looking at the custom documentation generator for date-fns got me thinking about whether there is a way to automatically generate documentation for RepoSense, especially for the CLI arguments and the configuration files. This would help new contributors understand the project better and also assist in maintaining up-to-date documentation. Although the work required to set up the documentation generator might be substantial, it could prove to be a worthwhile investment in the long run, particularly if well-documented.
3.3 New contributor issues
If we aim to attract more first-time contributors to NUS-OSS projects as opposed to long-term contributors, we could establish a system akin to checkstyle's approach by labelling issues as "good first issue," "good second issue," and so on. By doing this, RepoSense can streamline the onboarding process and foster a welcoming community for a diverse pool of contributors. This would also help in managing the influx of new contributors and ensure that they have a smooth onboarding experience.
DAVID GARETH ONG
Project: Recharts
Recharts is a React library that provides an easy way to write & render charts in React applications.
My Contributions
My first contribution was updating the Storybook page of the project. Storybook is a frontend workshop that allows users to render UI components and/or pages in isolation, and is often used for interactive documentation of each component in UI libraries. Within Recharts, in addition to the standard markdown-based documentation of its components, it maintains a Storybook page that documents each component interactively, as well as providing examples of how to achieve common use-cases with the components it provides.
In docs: add storybook example for line trailing icon in LineChart, I added an example of how to add a custom trailing icon to a line within a line chart, which was a common usecase that required a workaround.
My Learning Record
The observed workflow/process of this external project has a couple of extremely important differences to our internal project (RepoSense in particular), which I feel we can learn from to improve developer experience, reduce the likelihood of regressions, and speed up turnaround time.
Usage of git hooks
The project has set up automatic hooks (using Husky) that run before every commit and push. These hooks run the linter and automated tests, and prevent any user from pushing if the linter and/or tests fail. What this does is guarantee that by the time a pull request is open, there won't exist any lint or test errors. It is a very common occurence in RepoSense that a contributor will open a pull request, and only then be notified that their code has a bunch of lint errors (this is even more common in frontend PRs). The most likely reason for this is that the linter script in the frontend folder (npm run lint) is never run during self testing, resulting in newer contributors almost always not being aware of the presence of the lint checks until the first time they open a PR and the CI runs. We can potentially save a lot of headache by implementing automatic git hooks into RepoSense, at least for linting the frontend codebase at a minimum. This would also probably speed up turnaround/development time, since there usually is quite a lot of time wasted when reviewers have to ask contributors to fix their linting errors.
Snapshot testing
The project also utilizes snapshot testing in their automated tests. They use Vitest to run snapshot tests, which is a library that we're considering in RepoSense as well. Snapshot testing involves the automatic creation of snapshot files that stores the output at the time the tests were run, and compares future outputs to these refefrence values. The snapshot files are usually checked into version control, and can be examined alongside code changes. Here's an example of a snapshot file and snapshot check in the external project's codebase. This is definitely something that we can consider implementing within RepoSense, with the intention of preventing regressions.
Importance of good first issues
The project makes a great effort to properly tag & maintain a list of good first issues for newer contributors, which usually consist of smaller and easier issues that don't require deep knowledge of large portions of the codebase to tackle. This was crucial in enabling my experience of contributing, and we should look to paying more attention to this in RepoSense, especially for each new batch.
GOKUL RAJIV
Project: Pandoc
Pandoc is a Haskell library and command-line tool for converting between various document formats. It is a powerful tool that can convert between many different formats, including Markdown, LaTeX, HTML, and many others. It is also extensible, allowing for the creation of custom readers and writers for new formats. Pandoc has 31.8k stars on GitHub and is used widely by individuals for personal workflows and within deployment pipelines by larger organizations.
My Contributions
- Fixed an issue involving Pandoc's Texinfo Writer: Add @var support in Texinfo Writer #8534 (merged)
- Fixed an issue involving Pandoc's RST Reader: RST reader: fix figclass and align annotations for figures (merged)
My Learning Record
The Haskell tooling ecosystem (GHC, Cabal, Stack, Haskell LSP, etc) makes writing Haskell quite enjoyable. In particular, Haskell features like abstract data types, parametric polymorphism, and type inferencing make understanding and modifying code in a general and well-abstracted way really easy to do. The language also allows for strong editor tooling that also helps improve the developer experience. Contributing to Pandoc allowed me to get a deep look at practical Haskell in a widely adopted and loved tool—something I've always wanted to do.
Pandoc is also a really great and flexible tool that has taught me a great deal about software design practices. Pandoc has lofty goals of providing good document conversion from a large number of input formats to a really large number of output formats. This is done by converting to and from Pandoc's own document intermediate representation, which has a large subset of the intersection of features of the input and output formats. By being very clear about the extent and specification of the intermediate representation, it is easy for several developers to concurrently add, modify, and fix existing readers and writers by mapping the semantics of the source or target specification to those of the Pandoc intermediate representation. In general, being very clear and thorough with interfaces between software segments seems to be an important and crucial aspect of any sufficiently sophisticated system. To a first approximation, Pandoc does a really good job of picking good defaults for the output format; if users want additional customizability, they can have that by writing their own custom Lua filters.
Observations from contribution process
Great practices:
- The maintainer, John MacFarlane (a philosophy professor at Berkeley), and other core maintainers are incredibly active. Both my PRs got attention within a day. The first PR was merged in under a day, and the second PR was merged in under an hour! Fast and active review provides contributors with quick feedback and, personally, was a very strong motivator for making more contributions. I definitely see myself tackling deeper issues over the summer.
- Great user documentation: The user documentation is really thorough and covers just about everything a user might need to get started and to get going with advanced features like Lua filters.
good first issuetags are a great entry point to the codebase. They cover issues that can be tackled without a very deep understanding of the codebase, but that still familiarize the contributor with the workflow of dealing with an issue and adding tests.
Possible improvements:
- Since not as many people contribute to Pandoc (likely due to the Haskell learning curve) outside of the core team compared to other large open source projects, there has not been much of a need for PR workflow automation. While CI's are run, more checks could be conducted with bots and other tools provided by Github actions to automate more of the review process (as is quite common with most big open source projects).
- I found developer documentation to be a little lacking (again likely due to the small number of contributors). It would have been nice to see details of things like editor set-up with the Haskell LSP, build instructions for particular pandoc applications, and a more detailed look at the codebase architecture.
Suggestions for the internal project based on external project observations
- I think the biggest takeaway personally was the importance of active maintenance and support. A community is only as active as its maintainers, and knowing that work will be promptly reviewed is crucial for the life and longevity of the community. This is definitely something we can improve on with RepoSense. It is, however, certainly a challenge with nus-oss, given that students come and go fairly frequently and attention has to contend with school work and other activities.
- Experience with Pandoc and Haskell has convinced me that advanced-type systems and function style programming help programmers write safer and more resilient software. Unfortunately, Java's type system (even with newer versions) is not nearly as powerful as Haskell's and limits how far we can take these ideas. Nevertheless, we can make some progress with making Reposense easier to reason about with refactors involving immutability and optional monads.
MARCUS TANG XIN KYE
Project: Supabase
Overview
Supabase is a prominent open-source alternative to Firebase, aiming to replicate Firebase's features using enterprise-grade open-source tools. It offers a robust platform for developers to build scalable and reliable applications with ease.
Supabase Auth, part of the Supabase ecosystem, is a user management and authentication server written in Go. It facilitates key functionalities such as JWT issuance, Row Level Security with PostgREST, comprehensive user management, and a variety of authentication methods including email/password, magic links, phone numbers, and external providers like Google, Apple, Facebook, and Discord. Originating from Netlify's Auth codebase, it has since evolved significantly in terms of features and capabilities.
My Contributions
Below is a summary of my contributions to Supabase, on both Supabase/supabase and Supabase/gotrue (to be renamed to supabase/auth):
| Date | Achievement |
|---|---|
| 12/23 | Merged PR: [#19825] Update SIGNED_IN event documentation (#19974) |
| 12/23 | Created issue for discovered security vulnerability: signUp leaking existing user role #1365 |
| 12/23 | Merged PR: fix: sanitizeUser leaks user role (#1366) s |
| 12/23 | Created PR: [#880] Add function to get user by email identities (#1367) |
| 12/23 | Merged PR: fix: add check for max password length (#1368) |
| 12/23 | Discussion on potential solutions for: Email rate limit is triggered even in scenarios where an email doesn't end up being sent (#1236) |
My Learning Record
Through my contributions to Supabase, I've gained significant insights and knowledge:
- Go Programming: Deepened understanding of Go, navigating and contributing to a sizable codebase.
- Authentication Flows: Explored and learned various authentication mechanisms and flows.
- Docker Usage: Enhanced skills in utilizing Docker for development and deployment purposes.
Reflections on Contributing to Supabase
- Contributing Guide: The Supabase Contributing Guide was instrumental in familiarizing myself with the contribution process.
- Responsive Community: The responsiveness of the developer community greatly facilitated the contribution experience, as it made discussions for the PR easier
- Issue Management: My experience on Supabase emphasized the importance of maintaining issues, particularly for first time issues. There weren't many first time issues, and for some of them, they were no longer required even though they were still open. This resulted in wasted work on a no longer relevant issue.
- First-Come, First-Served Approach: Supabase chose to have a first come first served approach to issue assignment, which avoids the pitfall of issue hoarding or being occuipied by an inactive contributer, by being open to public contribution without explicit assignment.
Suggestions for Improvement
While my experience contributing to Supabase was largely positive, I identified areas for enhancement:
- Issue Management: There's a need for more active management of issues, especially those labeled for beginners, to prevent contributors from spending time on outdated or resolved issues.
Applying Supabase Practices to NUS-OSS Projects
From my engagement with Supabase, I've identified practices that could benefit NUS-OSS projects, particularly the use of Docker for simplifying project setup and ensuring consistency across development environments. This helped save alot of time by avoiding complicated manual setups, and allowed me to focus on resolving the issues.
TEAMMATES
CHANG WENG YEW, NICOLAS
Project: MermaidJS
JavaScript based diagramming and charting tool that renders Markdown-inspired text definitions to create and modify diagrams dynamically.
My Contributions
While setting up the MermaidJS code base I realised that the recommended VSCode extension for Vitest (Community made) was deprecated and was replaced with the updated version maintained by the Vitest team. I had then filed an issue and made a PR to update this(merged).
While understanding the codebase to solve this PR (to be solved) which involved adding additional funcionality to git diagrams, I realised that there was an undocumented feature that was merged a few versions ago. I had then filed an issue an added this to the documentation (merged)
I am in the process of converting gitGraph functions from JS to TS in this PR. This is how Mermaid maintains an internal structure of what should be rendered. This would then be followed up by another PR to change the language parser used from BISON to Langium, which provide nicer features for users.
My Learning Record
BISON/ Langium Parser Generator
I'm still in the midst of learning this, but I've learned that parsers can be generated using programs such as BISON and Langium. Mermaid is built on JIISON a BISON implementation in JS which has been unofficially deprecated and has been trying to make a move to move away from this to a maintained alternative Langium. I would be trying to learn BISON and rewrite some parts of the git graph parser to make it more flexible in allowing me to implement new features.
Resources: GNU BISON Documentation
Observations from contributing process
- Github Issues from users: Issues are initiated from the ground up from users and are discussed with maintainers
- Management of PRs: Maintainers will commit directly to the fork for branches if changes required are help push PRs to completion
- Detailed Issues: Extensive communication in the issues about design decisions and proposals are in the issue allowing new contributors to follow the thought process and pick it up if they are interested.
DOMINIC LIM KAI JUN
Project: freeCodeCamp
freeCodeCamp is an open-source codebase and curriculum to learn and code for free.
My Contributions
PR Link: https://github.com/freeCodeCamp/freeCodeCamp/pull/53233
My first PR in this project was improving the description and hint of a feature (i.e., Writing a function for the equivalent of =FORMULA in Excel) in a Spreadsheet Project.
My Learning Record
Tools/Technologies learned:
- Gitpod
Gitpod
This was the first time I have come across Gitpod (and it was the topic for my Lightning Talk in Round A2).
As freeCodecamp's codebase is extremely large, there are many different configurations and areas to get the project up and running locally. Hence, first-time contributors were encouraged to use Gitpod to start the project.
Observations from freeCodeCamp
- The set up was the most complicated that I have come across. There were many steps to do as it is a large project. However, the documentation is great such that it's comprehensive and concise in helping first time contributors to set up the project successfully. Alternatively to setting up locally, the team has integrated Gitpod into its project that really helped me as with limited time trying to speed up the contribution set up process.
- With a project that is this large scale, there is an active team available to manage and guide contributors i.e., Most issues and PRs are looked at rather quickly. However, overlapping with the previous point, the documentation speaks volumes and it helps saves developer productivity.
Project: date-fns
date-fns is a modern JavaScript date utility library. It provides the most comprehensive, yet simple and consistent toolset for manipulating JavaScript dates in a browser & Node.js.
My Contributions
PR Link: https://github.com/date-fns/date-fns/pull/3687
My first PR in this project was enhancing an existing function in the date-fns library. The action item was to create an alias for the more generic name that was initially given to the function.
My Learning Record
Tools/Technologies learned:
- How an npm package actually works
- This was my first time working on an npm package. I got to see and understand how a package is built and deployed onto the npm servers for use in other projects.
Observations from date-fns
- Compared to freeCodeCamp, it seems as though this project is managed by only 1 person. Responses on issues and PRs are rather slow (till this date, I am still waiting for a reply on my PR) which really is understandable.
- It lacks a contribution documentation too.
Project: stdlib
stdlib is a standard library for JavaScript and Node.js. It has an emphasis on numerical and scientific computing applications. This library provides a conglomerate of libraries for mathematics, statistics, data processing, streams, etc.
My Contributions
PR Link: https://github.com/stdlib-js/stdlib/pull/2008
My PR in this project was to add more examples into the math/iter/ops (iter == iterator, ops == operations) namespace and to provide examples on the usage in this library.
My Learning Record
Tools/Technologies learned:
- What's in a standard library for a programming language/framework
- This was my first time working on such a project. I got to see and understand what is in a standard library.
- Considering the fact that it's a standard library, the GNU Make tool comes in really handy and running most of the project's features e.g., Tests, installing dependencies, etc.
- The reason why I picked this namespace to work on was because I came across generators in Python when I was reading in some of the more advanced concepts of the language. I thought this will be a good opportunity to apply what I have learnt and I was able to understand how similar this stdlib's namespace is.
Observations from stdlib
- Similar to date-fns, this project is managed by 3-5 active contributors.
- Even though there is a small team managing this project, the issues management and responses to comments in them are great! Issues all around are well labelled.
- This project's contribution docs is only in a single README file, considering its scale, this suffices. It's actually really well written too, providing well rounded help in starting!
JAY ALJELO SAEZ TING
Project: Python (CPython)
Python is a high-level, general-purpose programming language. CPython is the reference implementation of the Python programming language. Written in C and Python, CPython is the default and most widely used implementation of the Python language.
My Contributions
gh-115323: Add meaningful error message for using bytearray.extend with str
I added a more meaningful error message when bytearray.extend is incorrectly used with a str object input, to tackle the bug highlighted in the GitHub issue, "bytearray.extend: Misleading error message".
str is a built-in type in Python. str objects are strings of text; strings are immutable sequences of Unicode code points. bytearray is another built-in type in Python; bytearray objects are mutable sequences of single bytes. bytearray.extend can be used to add all the bytes of another sequence of bytes to the end of the bytearray object. This means that bytearray.extend can only be used with inputs that are sequences of individual bytes. In other words, str objects cannot be used as input to bytearray.extend because they are not sequences of single bytes.
When a str object is passed as input into bytearray.extend, Python correctly raises an error due to the type of the input. However, the error message is misleading, as it states TypeError: 'str' object cannot be interpreted as an integer. The str object mentioned can be interpreted as referring to the input passed, which seems to suggest that integers can be passed as input, which is incorrect because integers are not sequences, much less sequences of bytes. In reality, the str object mentioned is referring to the elements of the sequence represented by the input str object, which are themselves also str objects.
The error message is not wrong. However, it is just misleading. The PR I contributed fixed this by doing a check when an error is raised for when the input is a str object, before changing the error message to a more meaningful one, which would be TypeError: expected iterable of integers; got: 'str'.
My Learning Record
Tools and technologies
reStructuredText (RST)
Python uses reStructuredText (RST) to document their project. RST is a lightweight markup language. It is not difficult to use, but it has its own syntax, which is different from the more popular markup languages like Markdown. I had to write a NEWS entry[1] using RST. I used the Python Developer's Guide page on RST to help me figure out how to write using RST.
Comparisons between the external project and the internal project
The Python project seems to care a lot more about performance
My first attempt at fixing the misleading error message was checking the type of the input very early on, even before any error was raised. I believe that in any other project, including in TEAMMATES, my first attempt might be seen as reasonable, and I think it might even be accepted, maybe after only a few minor changes, if any.
However, this was not the most performant way to fix the bug. Checking the type of the input before an error is raised means that the input would be checked even if the input was valid. The first review wanted me to change this, and so I did.
The Python project seems to document virtually every change into its changelog and highlights more important ones
When I made my PR to fix the misleading error message, I was also required to write a NEWS entry, just like almost every other PR made to the project. In the Python project, NEWS entries document contributions so that it can be added into the changelog. They are necessary for any contribution made, except for those that do not affect users of the Python programming language itself, including:
- documentation changes
- test changes
- strictly internal changes with no user-visible effects
- changes that already have a
NEWSentry - reverts that have not yet been included in any formal release (including alpha and beta releases)
From what I understand, changes that are more significant can be highlighted in "What's New in Python" entries.
In comparison, I do not think this is done in TEAMMATES. I think all the changes are mentioned equally in the releases.
The Python project has room to be less strict with minor contributions
If somebody wants to fix a typo in the Python project, they do not need to post a new issue before making a pull request. They can simply make the pull request immediately. From what I know, this is not the case in TEAMMATES. At the very least, it is not explicitly mentioned in the TEAMMATES developer guide.
The Python project automatically merges bug fixes on all its branches
When a Python version is released, people will use that version of Python. They may continue to use that version for their projects even when much newer Python versions are released. Thus, the Python team needs to continue to support older versions (up to a limit) by making sure that bug fixes, and security patches are also made to the supported older Python versions.
Each version is maintained on their own respective Git branch, but all changes are initially made by submitting a PR to the main branch. The PRs are given labels like needs backport to 3.12 which indicate whether the PR needs to be backported to a specific Git branch for a Python version. When a PR is merged into the main branch, a bot (miss-islington-app) backports it to older Python branches according to the labels. It does this by submitting the same PR to the Git branches of the relevant Python versions. A member of the Python project team can then merge the PR into the Git branches of the relevant Python versions.
In TEAMMATES, we may often have multiple feature branches in addition to the main branch. Fixes may be made to the main branch that are also required on the feature branches. In TEAMMATES, we often integrate these fixes into the feature branches by manually rebasing the feature branch onto the last commit on the main branch or merging the main branch into the feature branch. In other words, unlike in the Python project where changes in the main branch are almost automatically integrated into the other branches, in TEAMMATES, these changes to the main branch are manually integrated into other branches.
Suggestions for the internal project based on external project observations
Changelog with highlights
Instead of displaying all the changes equally, it may be better to highlight some of them, as they be more significant to more users. Users may not notice those changes if they are displayed equally with the rest, even it may be of interest to them.
Minor contributions should not require GitHub issues
For minor contributions, it seems like it would be overkill to need to post an issue before a pull request can be made. If it is not already the case, then maybe we should allow minor contributions without their own GitHub issues. We should also make it clear in the developer guide that this is allowed.
Automation to integrate changes in the main branch into the feature branches
Instead of manually rebasing onto the main branch or manually merging the main branch into a feature branch, maybe it would be better to do it automatically. Maybe a bot can do this for us. A problem I can foresee with this is if there are merge conflicts. However, it is possible to make a PR for merging branches. The merge conflicts may be resolved manually in the branch created for the PR. While this reintroduces some manual work, the merge conflicts should not occur all the time. If this automation is possible, with some of the changes in the main branch being integrated into the feature branches automatically, this may reduce some of the load on the developers.
KEVIN FOONG WEI TONG
Project: Scribe iOS
Scribe-iOS is a pack of iOS keyboards for language learners. It supports languages such as German, French, Italian etc. It supports features such as language translation to language of choice, singular to plural conversion and word suggestions. Language verbs and noun data is sourced from the Wikidata knowledge base.
Similar to TEAMMATES, Scribe is part of GSoc and part of the Wikimedia community (of which Wikipedia is the most well-known product).
My Contributions
Code quality improvements for Swift code I contributed by first going through open issues and managed to find some code improvement suggestions made. Then, I performed some code refactoring of the codebase to improve code quality.
My Learning Record
Using simulators
For tools learnt, as I am new to Swift/iOS/mobile programming, I learnt to set up the development environment needed which was new to me. This involves installing Xcode and setting up the emulator for verification of correctness.
Resources used:
This idea of simulators is new to me but reminiscent of the DevTools in web browsers such as Chrome. Interestingly, the simulators also provide a similar interface as browser devtools which allow developers to debug code.
Learning Swift programming
I also spent time learning a new programming language for my contribution, Swift, which introduces some new syntax not present in other programming languages like Java.
For example, instead of:
for (int i = 0; i < 3; i++) {
...
}
in Java. Swift introduces range operators
a..<b (includes value a, but excludes the value b) and a...b
a...b (includes both a and b)
This syntax is especially convenient as it allows us to do:
for 0..<3 instead
or with case statements:
case 0..<3:
print("Value within 0 and 2 inclusive)
case 4...5:
...
which is not possible with Java or C.
Resource: Hacking With Swift Tutorial, range operators
An interesting observation is that compared to other programming languages, Apple seems to invest heavily in its developer education community and tries to make learning Swift as fun as possible.
I experimented with the Swift Playgrounds, a gamified application by Apple to learn Swift as part of my learning journey to work on a Swift codebase. It allows one to learn Swift fundamentals through completing objectives through a game.
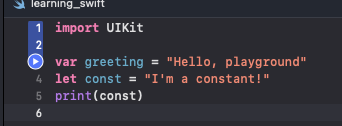
Apple has also made learning Swift a more intuitive experience by introducing a code evaluator in the playground environment directly which makes understanding Swift code a lot easier in the Xcode IDE.
As part of implementing code improvements, I also researched Swift conventions. I learnt that camelCase is the default convention used in Swift, read about preferences regarding Swift type inferencing etc.
Learnings for OSS practices from Scribe-iOS:
- Usage of public chat room
Since OSS projects usually accept contributions from developers from all over the world, Scribe uses an Matrix community chatroom to build a community and for all developers to join. This chatroom allows developers to introduce themselves, discuss issues related to development, raise suggestions and ask for help. This is a practice TEAMMATES might be able to adopt.
- Github actions automation for maintainer checklist

After each PR is made, an automated message encouraging contributors to join the abovementioned chat room and a bunch of checklist items are posted. This serves as a communication tool to new developers and serves as a friendly introduction to new committers which builds a more welcoming community.
Some useful info to include in such a message are:
- thank you message and crediting contributors for their efforts
- how to be involved in the community
- what to expect next after making a PR
- checklist for maintainers on protocol to handle PRs
- Changelog
Before changes are made, the CHANGELOG has to be updated with a description of the changes made. This allows releases to be documented and allows developers to keep track of what each version entails.
MOK KHENG SHENG FERGUS
Project: Litestar
Litestar is a powerful, flexible yet opinionated ASGI framework, focused on building APIs, and offers high-performance data validation and parsing, dependency injection, first-class ORM integration, authorization primitives, and much more that's needed to get applications up and running.
My Contributions
- Add reload-include and reload-exclude from uvicorn to CLI
- Fixing documentation bug
- Helped investigate a logging issue
My Learning Record
- Project outreach
Litestar's project outreach is one of the best that I've seen in any project. They are transparent about progress, and reach out to both users and contributers to encourage usage and contributions. Because Litestar is an ASGI framework that manages the majority of an application, it requires a large amount of effort and trust by users into the project.
For example, they regularly post updates on the Python subreddit on major milestone and releases. Furthermore, they hold regular office hours live, and recordings are also posted on YouTube. Furthermore, they maintain a very large pool of "Good First Issues" for contributers to start on. As of writing, they have 20 such issues open.
- Project management
Because Litestar is relatively new status compared to the very popular FastAPI, the maintainers have sought to prove the project's sustainability to their users.
For example, in the past few years, one of the goals were to increase bus size, to a minimum of 5. They've since achieved this, and their project has been stronger than ever. This is in contrast to FastAPI, which infamously has only a single maintainer, who refuses to take on more maintainers or accept PRs.
NEO WEI QING
Project: AncientBeast
AncientBeast is a turn-based strategy game that has been around for 13 years, with a small but active developer base and player community. It is played directly on the browser and supports various game modes including online multiplayer. The current version being worked on is v0.5.
My Contributions
I have mainly worked on the improvement of visuals, adding some information on the hexagon grid upon some user action.
My first issue was to show a 'Skip turn' icon when the user hovers over an active unit. To solve this issue (PR here), I added some assets to the assets loaded as well as an additional hint type. Then, I added the 'Skip turn' icon if the new hint type was called.
My second issue was to show the selected ability above the hovered hexagon when targeting the ability. This issue presented a different challenge, since the hint types above are only used for units. To solve this issue (PR here and still ongoing), I had to add the unit abilities to the assets, and then add an 'ability' class to the hovered hex's overlay visual state, removing the class as necessary. Then, I checked if the 'ability' class was present, got the appropriate ability asset, and set it to be shown above the hexagon. Unfortunately, due to some complications and a decision to focus more on TEAMMATES work, I have been unable to resolve some of the problems with the PR. I plan to complete it during the exam weeks.
Afterwards, I plan to take on this third issue after the PR above is merged, as it is makes use of the changes made in the above 2 PRs.
My Learning Record
AncientBeast makes use of Phaser as its game engine (which is also open source). Having had not much experience with game development, I found using Phaser quite challenging, and had to rely a lot on community help. I mainly learnt about how to manipulate GameObjects, such as Sprites, in Phaser as well as how they are animated and rendered.
Another thing I learnt about was testing a game's UI using Jest. The approach AncientBeast took relied mostly on getting game objects at certain x and y positions, as well as checking what existed at certain coordinates to ensure that actions were correctly handled. Some of the difficulties faced were in trying not to have tests depend too much on implementation (e.g. of Creatures in the game), and so tests had to be a bit more general.
More broadly, I learnt about game development in general. There is a lot more attention paid to anything that the user might try to do, including just hovering over something. I think this level of detail to user actions (and how it can be handled neatly in the codebase) is quite unique to game development.
Observations from AncientBeast
Unfortunately, I think AncientBeast's code is quite messy. The files are long, variables are sometimes inappropriately named (e.g. some are just named o), and basically a lot of functionality is packed together in one place, reducing readability. There are deprecated calls as well, which I think should be fixed together with the deprecation. Furthermore, there is a lack of developer documentation, which further poses a challenge to new contributors. For example, I think I would have greatly benefitted from some flows of standard actions, or generally how classes interact with each other. Better documentation might also lead to better structuring of code, which AncientBeast needs. Another point of improvement would be type safety, since I found that quite a few variables are just typed as any.
That being said, I think AncientBeast does well in contributor management. Once someone expresses an interest in an issue, they will be assigned it and given a soft deadline, usually of 2 weeks. If they cannot complete it and/or are unresponsive, then the issue will usually be assigned to someone else, or just left without an assignee, indicating that it is available. I think we could benefit from implementing a similar approach, else our issues get inundated with "is this issue still available?" comments and waiting for people to say whether or not they are still working on it. The soft deadline also helps to push progress along.
Another thing we could adopt is having a standardised code format. I've noticed many discrepancies in coding style throughout our codebase, and I think having a standardised coding style (with non-controversial rules) would make our code neater and in some cases more readable.
ONG JUN HENG, CEDRIC
Project: Mattermost
Mattermost is an open-source alternative to slack and mircosoft teams, used by notable companies such as Samsung, NASA, DuckDuckGo. Mattermost is self-deployable and enables full control over one's data. Mattermost has many intergrations with tools such as GitHub, Jenkins, Jira, to enable technical teams to collaborate more productively.
My Contributions
Contributed 2 PRs to Mattermost's mobile application:
The first was a UX bug fix: link, where the save button on editing a message was not greyed out when the message was too long. To solve this, I edited the styling of the button, changing its opacity for when its disabled. I then replicated the issue locally to add a screenshot to my PR.
The second was removal of a feature flag: link, to enable timezone support permanently in the application.
To tackle this issue, I had to look at every location where there the feature flag was used in the codebase. When removing the flag, I had to make sure that the logic was correct, behaving as if the feature flag was true and that irrelevant code was removed.
My Learning Record
React Native
The technology used in Mattermost's mobile application is React Native. React Native is a framework for building mobile applications using Javascript and React, and allows developers to create cross-platform applications for iOS and android using a single codebase. React Native utilizes native components and APIs, providing a user experience similar to native apps.
I used React Native's documentation to learn more about it while contributing.
Observations from Mattermost
- PRs are reviewed extensively, with clear steps. Each step is labelled clearly. (Dev Review, QA review, PM review) TEAMMATES also has a similar system in place in terms of labelling the stage of a PR review.
- Issues are labelled with the technology required (e.g. React, ReactNative, go), the difficulty level (from 1-4), and whether it is currently being worked on by someone. This makes it easier for potential contributors to select issues based on their own confidence level. In TEAMMATES, we only have
good first issueas any indicator of difficulty level, but given that most difficult issues are handled by the internal team, there is unlikely a need for difficulty level. For technology required, TEAMMATES also does not have a label, but it should be quite clear when reading the issue if it requires Backend or Frontend. TEAMMATES also has aa-UIXtag that is meant for UIUX related issues, which is very often used to tag Frontend issues. - Mattermost also has their own deployed instance of itself, where contributors can ask questions. It was really useful for me when I ran into issues trying to login to my locally setup Mattermost, and asking for PR reviews. TEAMMATES does not have this, but it would be really costly for us to maintain.
SIM SING YEE, EUNICE
Project: stdlib-js
- Project: stdlib-js stdlib-js is a standard library for JavaScript and Node.js. It mainly provides numerical and scientific functionality, with robust performance.
My Contributions
- Merged PR: Improve documentation for
math/base/opsnamespace This documentation was user-facing. It was meant for users of the software to get a good understanding of what this package of the library provides and any interesting usage examples. While working on this
My Learning Record
The codebase was very well documented, with very clear-cut instructions of how to set up the library, the standard practices for developers (including testing documentation and code quality expectations).
- make: make was used for this project, not only to build executables but also to install dependencies, initialise git hooks, etc.
- "Sign off and commit suggestion" (cool! allow devs to merge in code directly from ):
For very simple and small changes required, we can create a hook that can apply changes / suggestions from reviewers.
Although we do hope for new contributors to get this chance to learn about teammates' coding practices, in other instances and for minor nits: it can significantly speed up time taken to merge in PRs if the author does not need to manually make the changes in their branch and push again.
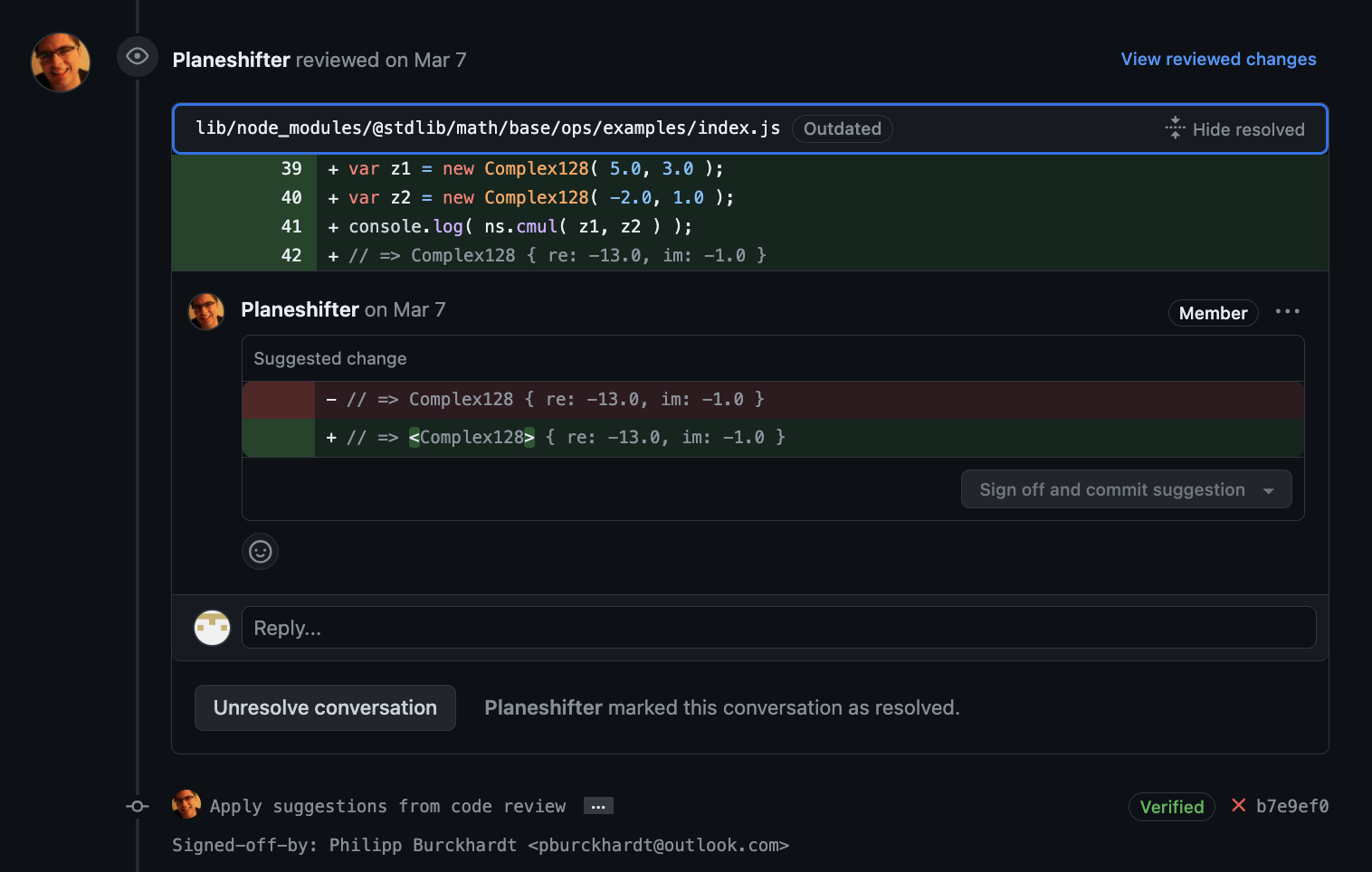
- very well-structured pipelines and application structure (easy to set up, test, lint, etc; clear and concise documentation)
ZHANG ZIQING
Project: Refine
Refine is a React Framework for building internal tools, admin panels, dashboards & B2B apps with unmatched flexibility. It uses TypeScript. It simplifies the development process and eliminate repetitive tasks by providing industry-standard solutions for crucial aspects of a project, including authentication, access control, routing, networking, state management, and i18n.
My Contributions
PR 1: docs(core): add DataProvider interface definition #5653
Initially I thought contributing to documentation is easy, but I realize that contributing to documentation requires good understanding of the codebase structure and the workflow.
My Learning Record
Give tools/technologies you learned here. Include resources you used, and a brief summary of the resource.
The PR review process in Refine is surprisingly fast. My PR is reviewed within one week.
Observations of contributing process:
Issues that are labelled good-first-issues often have comments that ask to be assigned the tasks. But the maintainers tend to take long to reply them. At the time they got back to potential contributers, contributers might already not be interested in it.
Refine has a Changeset system where contributors need to label the impact on packages such as whether it requires a major version bump in any packages, as Refine uses a monorepo structure.
Refine is well-documented and its core team is quite active in issues, which is a hugh advantage for first time contributers because their questions got answered immediately. However, their good-first-issues still have high barriers to entry because of the complicated code structure. That being said, their maintainers make a good effort to explain what might need to be done to submit a PR in the issues, making it easier to understand.
In the Python project,
NEWSentries document contributions so that it can be added into the changelog.